Latest Articles
29 Mar 2024 : Clinical Research
Questionnaire-Based Study of 392 Women in Abbottabad, Pakistan, to Evaluate the Types of Cosmetic Products Purchased Between December 2018 and March 2019 and Their Associated Adverse Events
Fatima Nisar, Atif Ali
DOI: 10.12659/MSMBR.943048
Med Sci Monit Basic Res 2024; 30:e943048






29 Mar 2024 : Clinical Research
Questionnaire-Based Study of 392 Women in Abbottabad, Pakistan, to Evaluate the Types of Cosmetic Products Purchased Between December 2018 and March 2019 and Their Associated Adverse Events
Fatima Nisar, Atif Ali
DOI: 10.12659/MSMBR.943048
Med Sci Monit Basic Res 2024; 30:e943048

01 Mar 2024 : Clinical Research
Levels of Depression, Anxiety, and Stress Among Saudi Arabia's Medical and Dental Practitioners: A Cross-Sectional Study Following the Covid-19 Pandemic
Ahmad H. Jabali, Hemant Ramesh Chourasia ![]()
DOI: 10.12659/MSMBR.942676
Med Sci Monit Basic Res 2024; 30:e942676
01 Mar 2024 : Clinical Research
Levels of Depression, Anxiety, and Stress Among Saudi Arabia's Medical and Dental Practitioners: A Cross-Sectional Study Following the Covid-19 Pandemic
Ahmad H. Jabali, Hemant Ramesh Chourasia ![]()
DOI: 10.12659/MSMBR.942676
Med Sci Monit Basic Res 2024; 30:e942676

20 Nov 2023 : Laboratory Research
Evaluation of the Effects of Digital Manufacturing, Preparation Taper, Cement Type, and Aging on the Color Stability of Anterior Provisional Crowns Using Colorimetry
Mohammed E. Sayed ![]() , Honey Lunkad
, Honey Lunkad ![]() Khurshid Mattoo
Khurshid Mattoo ![]() , Hossam F. Jokhadar
, Hossam F. Jokhadar ![]() , Saad Saleh AlResayes
, Saad Saleh AlResayes ![]() , Nasser M. Alqahtani
, Nasser M. Alqahtani ![]() , Abdullah Hasan Alshehri
, Abdullah Hasan Alshehri ![]() , Mohammad Alamri
, Mohammad Alamri ![]() , Sultan Altowairqi
, Sultan Altowairqi ![]() , Muhannad Muaddi
, Muhannad Muaddi ![]() , Halah Mohammed Huthan
, Halah Mohammed Huthan ![]() , Safeyah Abdulrahman Baeshen
, Safeyah Abdulrahman Baeshen ![]() , Khalid Motlaq
, Khalid Motlaq ![]() , Amal M. Masmali
, Amal M. Masmali ![]() - Show fewer authors
- Show fewer authors
DOI: 10.12659/MSMBR.941919
Med Sci Monit Basic Res 2023; 29:e941919

20 Nov 2023 : Laboratory Research
Evaluation of the Effects of Digital Manufacturing, Preparation Taper, Cement Type, and Aging on the Color Stability of Anterior Provisional Crowns Using Colorimetry
Mohammed E. Sayed ![]() , Honey Lunkad
, Honey Lunkad ![]() Khurshid Mattoo
Khurshid Mattoo ![]() , Hossam F. Jokhadar
, Hossam F. Jokhadar ![]() , Saad Saleh AlResayes
, Saad Saleh AlResayes ![]() , Nasser M. Alqahtani
, Nasser M. Alqahtani ![]() , Abdullah Hasan Alshehri
, Abdullah Hasan Alshehri ![]() , Mohammad Alamri
, Mohammad Alamri ![]() , Sultan Altowairqi
, Sultan Altowairqi ![]() , Muhannad Muaddi
, Muhannad Muaddi ![]() , Halah Mohammed Huthan
, Halah Mohammed Huthan ![]() , Safeyah Abdulrahman Baeshen
, Safeyah Abdulrahman Baeshen ![]() , Khalid Motlaq
, Khalid Motlaq ![]() , Amal M. Masmali
, Amal M. Masmali ![]() - Show fewer authors
- Show fewer authors
DOI: 10.12659/MSMBR.941919
Med Sci Monit Basic Res 2023; 29:e941919
06 Nov 2023 : Original article
Urinary Klotho Excretion: A Key Regulator of Sodium Homeostasis in Chronic Kidney Disease Stage 2-4
Po-Jui Chi, Chung-Jen Lee Shih-Yuan Hung ![]() , Jen-Pi Tsai, Hung-Hsiang Liou - Show fewer authors
, Jen-Pi Tsai, Hung-Hsiang Liou - Show fewer authors
DOI: 10.12659/MSMBR.942097
Med Sci Monit Basic Res 2023; 29:e942097
06 Nov 2023 : Original article
Urinary Klotho Excretion: A Key Regulator of Sodium Homeostasis in Chronic Kidney Disease Stage 2-4
Po-Jui Chi, Chung-Jen Lee Shih-Yuan Hung ![]() , Jen-Pi Tsai, Hung-Hsiang Liou - Show fewer authors
, Jen-Pi Tsai, Hung-Hsiang Liou - Show fewer authors
DOI: 10.12659/MSMBR.942097
Med Sci Monit Basic Res 2023; 29:e942097
30 Oct 2023 : Original article
Exploring the Impact of the COVID-19 Pandemic on Academic Burnout Among Nursing College Students in China: A Web-Based Survey
Huan Liu ![]() , Ziyu Zhang
, Ziyu Zhang ![]() Chenru Chi
Chenru Chi ![]() , Xiubin Tao
, Xiubin Tao ![]() , Ming Zhang
, Ming Zhang ![]() - Show fewer authors
- Show fewer authors
DOI: 10.12659/MSMBR.940997
Med Sci Monit Basic Res 2023; 29:e940997
30 Oct 2023 : Original article
Exploring the Impact of the COVID-19 Pandemic on Academic Burnout Among Nursing College Students in China: A Web-Based Survey
Huan Liu ![]() , Ziyu Zhang
, Ziyu Zhang ![]() Chenru Chi
Chenru Chi ![]() , Xiubin Tao
, Xiubin Tao ![]() , Ming Zhang
, Ming Zhang ![]() - Show fewer authors
- Show fewer authors
DOI: 10.12659/MSMBR.940997
Med Sci Monit Basic Res 2023; 29:e940997
18 May 2023 : Clinical Research
Anxiety and Depression Survey and Analysis of Hospital Staff in a Designated Hospital in Shannan City During the COVID-19 Pandemic
Peijin Zhang, Liling Tang
DOI: 10.12659/MSMBR.939514
Med Sci Monit Basic Res 2023; 29:e939514
18 May 2023 : Clinical Research
Anxiety and Depression Survey and Analysis of Hospital Staff in a Designated Hospital in Shannan City During the COVID-19 Pandemic
Peijin Zhang, Liling Tang
DOI: 10.12659/MSMBR.939514
Med Sci Monit Basic Res 2023; 29:e939514
22 Mar 2023 : Clinical Research
A Questionnaire-Based Study to Compare the Psychological Effects of 6 Weeks of Exercise in 123 Chinese College Students
Mei Xue Wei, Zhen Liu
DOI: 10.12659/MSMBR.939096
Med Sci Monit Basic Res 2023; 29:e939096
22 Mar 2023 : Clinical Research
A Questionnaire-Based Study to Compare the Psychological Effects of 6 Weeks of Exercise in 123 Chinese College Students
Mei Xue Wei, Zhen Liu
DOI: 10.12659/MSMBR.939096
Med Sci Monit Basic Res 2023; 29:e939096

08 Mar 2023 : Clinical Research
Study of 60 Adult Patients to Compare Standard Postoperative Clinical Assessment with Train-of-Four Ratio ≥0.9 on Patient Outcomes Using Postoperative Spirometry and Neuromuscular Function Measurements Following Extubation
Chunlong Chen, Qingzhen Liu
DOI: 10.12659/MSMBR.938849
Med Sci Monit Basic Res 2023; 29:e938849

08 Mar 2023 : Clinical Research
Study of 60 Adult Patients to Compare Standard Postoperative Clinical Assessment with Train-of-Four Ratio ≥0.9 on Patient Outcomes Using Postoperative Spirometry and Neuromuscular Function Measurements Following Extubation
Chunlong Chen, Qingzhen Liu
DOI: 10.12659/MSMBR.938849
Med Sci Monit Basic Res 2023; 29:e938849
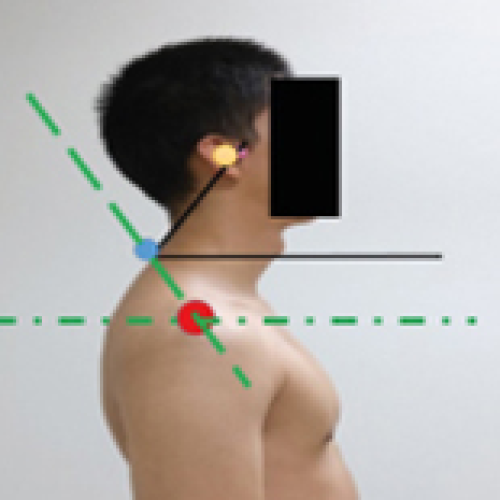
07 Feb 2023 : Clinical Research
A Prospective Study of 73 Patients to Compare Forward Head Angle, Forward Shoulder Angle, Maximal Inspiratory Pressure, and Self-Reported Breathing-Related Symptoms Before and After Open-Heart Surgery
Bussakorn Thanasarn, Wittawat Pibul
DOI: 10.12659/MSMBR.938802
Med Sci Monit Basic Res 2023; 29:e938802
07 Feb 2023 : Clinical Research
A Prospective Study of 73 Patients to Compare Forward Head Angle, Forward Shoulder Angle, Maximal Inspiratory Pressure, and Self-Reported Breathing-Related Symptoms Before and After Open-Heart Surgery
Bussakorn Thanasarn, Wittawat Pibul
DOI: 10.12659/MSMBR.938802
Med Sci Monit Basic Res 2023; 29:e938802
10 Jan 2023 : Clinical Research
Prevalence and Associated Factors of Depression Among Frontline Nurses in Wuhan 6 Months After the Outbreak of COVID-19: A Cross-Sectional Study
Huan Liu ![]() , Zhiqing Zhou
, Zhiqing Zhou ![]() Yan Liu
Yan Liu ![]() , Xiubin Tao
, Xiubin Tao ![]() , Yuxin Zhan
, Yuxin Zhan ![]() , Ming Zhang
, Ming Zhang ![]() - Show fewer authors
- Show fewer authors
DOI: 10.12659/MSMBR.938633
Med Sci Monit Basic Res 2023; 29:e938633
10 Jan 2023 : Clinical Research
Prevalence and Associated Factors of Depression Among Frontline Nurses in Wuhan 6 Months After the Outbreak of COVID-19: A Cross-Sectional Study
Huan Liu ![]() , Zhiqing Zhou
, Zhiqing Zhou ![]() Yan Liu
Yan Liu ![]() , Xiubin Tao
, Xiubin Tao ![]() , Yuxin Zhan
, Yuxin Zhan ![]() , Ming Zhang
, Ming Zhang ![]() - Show fewer authors
- Show fewer authors
DOI: 10.12659/MSMBR.938633
Med Sci Monit Basic Res 2023; 29:e938633
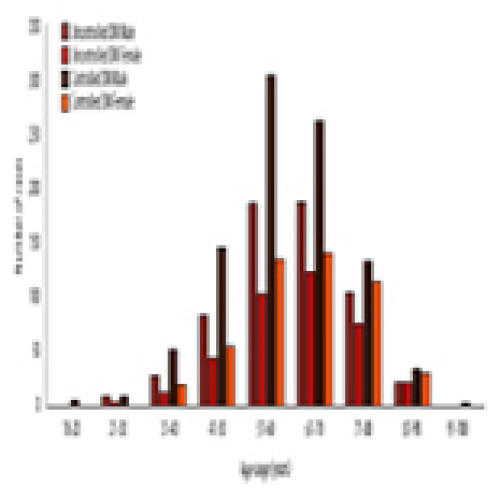
08 Dec 2022 : Original article
Use of Estimated Glomerular Filtration Rate and Urine Albumin-to-Creatinine Ratio Based on KDIGO 2012 Guideline in a Thai Community Hospital: Prevalence of Chronic Kidney Disease and its Risk Factors
Veeravan Lekskulchai,
DOI: 10.12659/MSMBR.938176
Med Sci Monit Basic Res 2022; 28:e938176
08 Dec 2022 : Original article
Use of Estimated Glomerular Filtration Rate and Urine Albumin-to-Creatinine Ratio Based on KDIGO 2012 Guideline in a Thai Community Hospital: Prevalence of Chronic Kidney Disease and its Risk Factors
Veeravan Lekskulchai,
DOI: 10.12659/MSMBR.938176
Med Sci Monit Basic Res 2022; 28:e938176

24 Nov 2022 : Clinical Research
FLT3 Gene Mutations in Acute Myeloid Leukemia Patients in Northeast Thailand
Nang Ei Ei Aung, Supawadee Yamsri Nattiya Teawtrakul, Piyawan Kamsaen, Supan Fucharoen ![]() - Show fewer authors
- Show fewer authors
DOI: 10.12659/MSMBR.937446
Med Sci Monit Basic Res 2022; 28:e937446

24 Nov 2022 : Clinical Research
FLT3 Gene Mutations in Acute Myeloid Leukemia Patients in Northeast Thailand
Nang Ei Ei Aung, Supawadee Yamsri Nattiya Teawtrakul, Piyawan Kamsaen, Supan Fucharoen ![]() - Show fewer authors
- Show fewer authors
DOI: 10.12659/MSMBR.937446
Med Sci Monit Basic Res 2022; 28:e937446

03 Nov 2022 : Laboratory Research
Evaluation of Antimicrobial Effectiveness of Dental Cement Materials on Growth of Different Bacterial Strains
Zana D. Lila-Krasniqi ![]() , Rrezarta Bajrami Halili Valeza Hamza, Sokol Krasniqi
, Rrezarta Bajrami Halili Valeza Hamza, Sokol Krasniqi ![]() - Show fewer authors
- Show fewer authors
DOI: 10.12659/MSMBR.937893
Med Sci Monit Basic Res 2022; 28:e937893

03 Nov 2022 : Laboratory Research
Evaluation of Antimicrobial Effectiveness of Dental Cement Materials on Growth of Different Bacterial Strains
Zana D. Lila-Krasniqi ![]() , Rrezarta Bajrami Halili Valeza Hamza, Sokol Krasniqi
, Rrezarta Bajrami Halili Valeza Hamza, Sokol Krasniqi ![]() - Show fewer authors
- Show fewer authors
DOI: 10.12659/MSMBR.937893
Med Sci Monit Basic Res 2022; 28:e937893
Most Viewed Current Articles
15 Jun 2022 : Clinical Research
Evaluation of Apical Leakage After Root Canal Obturation with Glass Ionomer, Resin, and Zinc Oxide Eugenol ...DOI :10.12659/MSMBR.936675
Med Sci Monit Basic Res 2022; 28:e936675
07 Jul 2022 : Laboratory Research
Cytotoxicity, Apoptosis, Migration Inhibition, and Autophagy-Induced by Crude Ricin from Ricinus communis S...DOI :10.12659/MSMBR.936683
Med Sci Monit Basic Res 2022; 28:e936683
01 Jun 2022 : Laboratory Research
Comparison of Sealing Abilities Among Zinc Oxide Eugenol Root-Canal Filling Cement, Antibacterial Biocerami...DOI :10.12659/MSMBR.936319
Med Sci Monit Basic Res 2022; 28:e936319
08 Dec 2022 : Original article
Use of Estimated Glomerular Filtration Rate and Urine Albumin-to-Creatinine Ratio Based on KDIGO 2012 Guide...DOI :10.12659/MSMBR.938176
Med Sci Monit Basic Res 2022; 28:e938176